
?
作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
互联网数据信息的大爆炸时代,每天都会有大量的数据产生、传播和积累,对于社交网络而言更是如此,微博很早就已经成为了信息的集中地,很多基于微博数据的分析研究工作都已经陆续开展了,本文主要是基于自己研究期间的分析工作进行简单的实践讲解说明,实现基于微博数据的人物性格分类系统。
项目整体流程示意图如下所示:
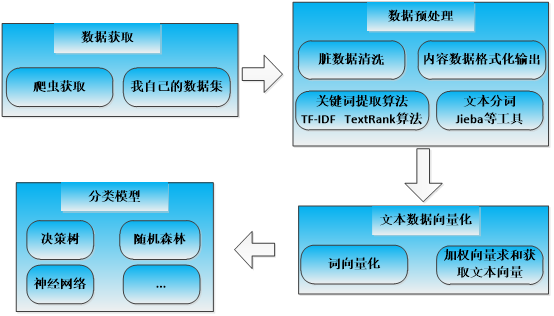
主要分成四个部分,分别是:数据采集与获取模块、数据预处理模块、文本数据向量化模块和分类模型。接下来针对各个部分进行详细的说明与讲解。
一、数据获取部分
最早开始的时候微博数据的开放度还是比较高的,所以采集和获取难度不是很大,也积累了一定的数据资源,之后相应的API接口都关闭了,而且现在官方的反扒措施十分严格导致大批量的数据采集工作难以有效地长时间地去开展,所以这里的数据集采取的是历史数据资源,当然,微博实时数据小批量的采集爬虫是比较简单的,感兴趣的话可以直接去我的博客里面拿去使用,这里不拿出来单独进行讲解了。
二、文本数据预处理
由于网络用语的随意性和不规范性导致爬取得到的微博数据集中存在很多无效字符、脏数据等信息,影响后续的使用,且原始的数据格式需要经过解析处理后才能转化为格式化的数据进行使用,这里首先需要对原始的文本数据进行预处理工作,具体的代码实现如下所示:
def data_prepossing(one_line):
'''
数据内容去除无效字符,预处理
去除:市、省 字符
过滤掉名字只有一个字的情况
one_line:单条企业名称数据
'''
sigmod_list=[',','。','(',')','-','——','\n','“','”','*','#','《','》','、','[',']','(',')','-',
'.','/','】','【','……','!','!',':',':','…','@','~@','~','「一」','「','」',
'?','"','?','~','_',' ',';','◆','①','②','③','④','⑤','⑥','⑦','⑧','⑨','⑩',
'⑾','⑿','⒀','⒁','⒂','"']
for one_sigmod in sigmod_list:
one_line=one_line.replace(one_sigmod,'')
if 'http' in one_line:
one_line=one_line.split('http')[0].strip()
if 'https' in one_line:
one_line=one_line.split('https')[0].strip()
return one_line
得到相对干净的数据之后我们就可以进行微博文本数据的分词处理,这部分主要是借助于结巴中文分词处理工具实现的,完成分词工作后如果需要进一步的分析文本内容可以基于TF-IDF和TextRank算法实现了关键词的挖掘计算和权重计算,具体的代码实现如下所示:
def seg(one_content,stopwords):
'''
分词并去除停用词
one_content:单条企业名称数据
stopwords:停用词列表
'''
segs=jieba.cut(one_content,cut_all=False)
segs=[w.encode('utf8') for w in list(segs)]# 特别注意此处转换
seg_set=set(set(segs)-set(stopwords))
return seg_set
def append_self_invalid_words(invalid_words='self_invalid_words.txt'):
'''
添加自己想去除的词语文件(文件中每一行是一个词语)
'''
if invalid_words is None:
word_list=[]
else:
with open(invalid_words) as f:
word_list=[one.strip() for one in f.readlines()]
print word_list
return word_list
def splitData2Words(data_list,invalidwords=None,stopwords=None):
'''
加载数据,对数据指定字段(语料)分词存储
'''
if stopwords is None:
stopwords_list=[]
else:
with open(stopwords) as s:
stopwords_list=[one.strip() for one in s.readlines()]
self_invalid_words_list=append_self_invalid_words(invalid_words=invalidwords)
print len(stopwords_list)
if stopwords_list and self_invalid_words_list:
stopwords_list+=self_invalid_words_list
elif stopwords_list:
pass
else:
stopwords_list=self_invalid_words_list
print len(stopwords_list)
content_list=[]
for i in range(len(data_list)):
one_content=data_prepossing(data_list[i].strip())
one_handle=seg(one_content,stopwords_list)
one_line='/'.join(one_handle)
content_list.append(one_line)
return content_list
上述代码实现了微博文本数据的分词工作,得到原始文本的分词结果后就可以进行词向量转化计算了。
三、文本向量化计算
微博文本的向量化工作主要是基于word2vec的加权词向量化进行计算的,首席基于word2vec实现词库语料数据的向量化计算,之后基于加权向量相加的形式实现文本向量化表示,具体的代码实现如下所示:
def word2vecModel(data='data/use_handle_split/1007939525.txt',num=10,model_path='my.model'):
'''
class gensim.models.word2vec.Word2Vec(sentences=None,size=100,alpha=0.025,window=5, min_count=5,max_vocab_size=None, sample=0.001,seed=1, workers=3,min_alpha=0.0001, sg=0, hs=0, negative=5, cbow_mean=1,hashfxn=<built-in function hash>,iter=5,null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000)
'''
with open(data) as f:
data_list=[one.strip().split('/') for one in f.readlines() if one]
con_list=[one for one in data_list if len(one)>=num]
model=word2vec.Word2Vec(con_list,sg=1,size=100,window=5,min_count=1,
negative=3,sample=0.001, hs=1,workers=4)
model.save(model_path)
return con_list,model
def getDocVec(model,word_list=['很','好吃','团鱼']):
'''
生成单个文本内容的向量(所有词向量加权求和)
'''
vec=np.array([0]*100,dtype='float32')
for word in word_list:
vec+=model[word]
return (vec/len(word_list)).tolist()
def vectorMainFunc(dataDir='data/use_handle_split/',save_path='feature.json'):
'''
文档向量化主函数
'''
txt_list=os.listdir(dataDir)
id_list=[one.strip().split('.')[0].strip() for one in txt_list]
map_dict={}
res_list=[]
for i in range(len(id_list)):
map_dict[id_list[i]]=i
for one_txt in txt_list:
one_path=dataDir+one_txt
one_id=one_txt.split('.')[0].strip()
con_list,model=word2vecModel(data=one_path,num=10,model_path='models/'+one_id+'.model')
for one_doc in con_list:
one_doc_vec=getDocVec(model,word_list=one_doc)
one_doc_vec.append(map_dict[one_id])
res_list.append(one_doc_vec)
with open(save_path,'wb') as f:
f.write(json.dumps(res_list))
经过上述代码的转化计算后,我们就得到了原始文本语料数据对应的特征向量表示,之后就可以用于分类模型进行分类计算了。
四、文本分类模型
文本分类模型这里的模型主要选用了决策树模型和随机森林模型,比较基础,这里就不做过多的说明了,具体的代码实现如下:
def DTModel(data='feature.json',rationum=0.30,model_path='Results/DT.pkl'):
'''
使用决策树模型
'''
with open(data) as f:
data_list=json.load(f)
print data_list[0]
x_list=[one[:-1] for one in data_list]
y_list=[one[-1] for one in data_list]
X_train,X_test,y_train,y_test=split_data(x_list, y_list,ratio=rationum)
DT=DecisionTreeClassifier()
DT.fit(X_train,y_train)
y_predict=DT.predict(X_test)
print ('DT model accuracy: ', DT.score(X_test,y_test))
saveModel(DT,save_path=model_path)
def RFModel(data='feature.json',rationum=0.30,model_path='Results/DT.pkl'):
'''
使用随机森林模型
'''
with open(data) as f:
data_list=json.load(f)
print data_list[0]
x_list=[one[:-1] for one in data_list]
y_list=[one[-1] for one in data_list]
X_train,X_test,y_train,y_test=split_data(x_list, y_list,ratio=rationum)
RF=RandomForestClassifier()
RF.fit(X_train,y_train)
y_predict=RF.predict(X_test)
print ('RF model accuracy: ', RF.score(X_test,y_test))
saveModel(RF,save_path=model_path)
上面四个部分的详细工作也都给出了具体的代码实现,感兴趣的话可以实践一下,在实验部分,我选取了4个id的数据,表示四种不同的性格,为了能够更加直观地看出来不同性格的数据形态,我们基于词云做了一个简单的展示,具体如下所示:
性格1:

性格2:

性格3:

性格4:

感觉区分度还是比较高的,我们针对决策树的分类结果做了一个简单的可视化分析,具体如下所示:
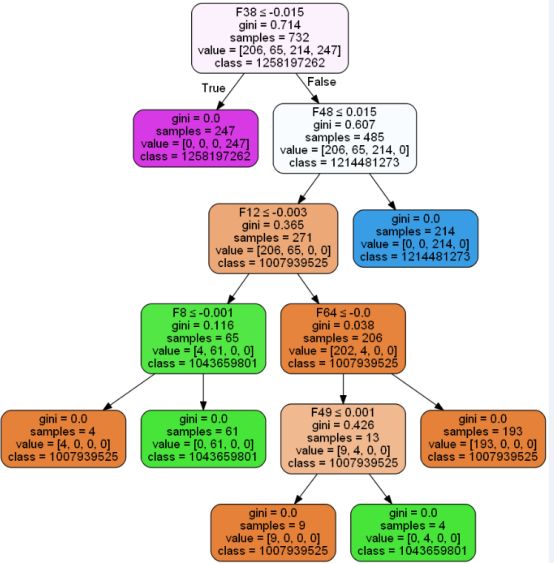
到这里本文的工作就结束了,很高兴在自己温习回顾知识的同时能写下点分享的东西出来,如果说您觉得我的内容还可以或者是对您有所启发、帮助,还希望得到您的鼓励支持!
觉得不错,点个在看呗!


